Post-Deployment Sentinel and Defender XDR: You're Not Done Yet

Alright, class.
So you've deployed Sentinel. You've got Defender XDR running. Your SOC is live. Alerts are coming in. Your Secure Score went up. You probably told your boss it's all done and you can relax now.
You can't.
Your Sentinel instance right now is like a Ferrari you just bought and parked in your garage, leaving it for a few months. It looks great. Everyone thinks you've got this covered. But you haven't serviced it once, the engine's cold, and if you actually try to drive it tomorrow, it's going to be a disaster.
The problem isn't deployment. The problem is what comes after.
The Thing Nobody Talks About
Most organisations will tell you their Sentinel is deployed and working. When you ask them, "How many false positives are you getting?" they go quiet. When you ask, "How often are your analysts tuning the rules?" they get uncomfortable. When you ask, "What data are you ingesting that you're not actually using?" they usually don't know.
The reality is simpler than that: you deployed Sentinel with out-of-the-box rules, it's firing thousands of alerts, half of them are rubbish, and your SOC team has started tuning them out, which is worse than having no alerts at all.
You know why? Because when the real breach happens, it's buried in the noise.
This is where it all falls apart for most organisations. They think the deployment is the hard part. The actual hard part is keeping the damn thing running properly.
Rule Tuning Is Not Optional
Your biggest problem right now is alert fatigue. Your SOC team has stopped reading alerts (don't lie to yourself, that it's otherwise) because they're getting hundreds of them a day, and 90% are garbage.
So here's what you need to do. Go to Microsoft Sentinel (Defender) > Configuration > Analytics and look at your rules. Find the ones firing the most alerts. Those are your problems.
You can find it easily with KQL like one below;
SecurityIncident
| where CreatedTime >= ago(90d) and CreatedTime <= now()
| summarize Total=dcount(IncidentNumber) by Title
| order by Total desc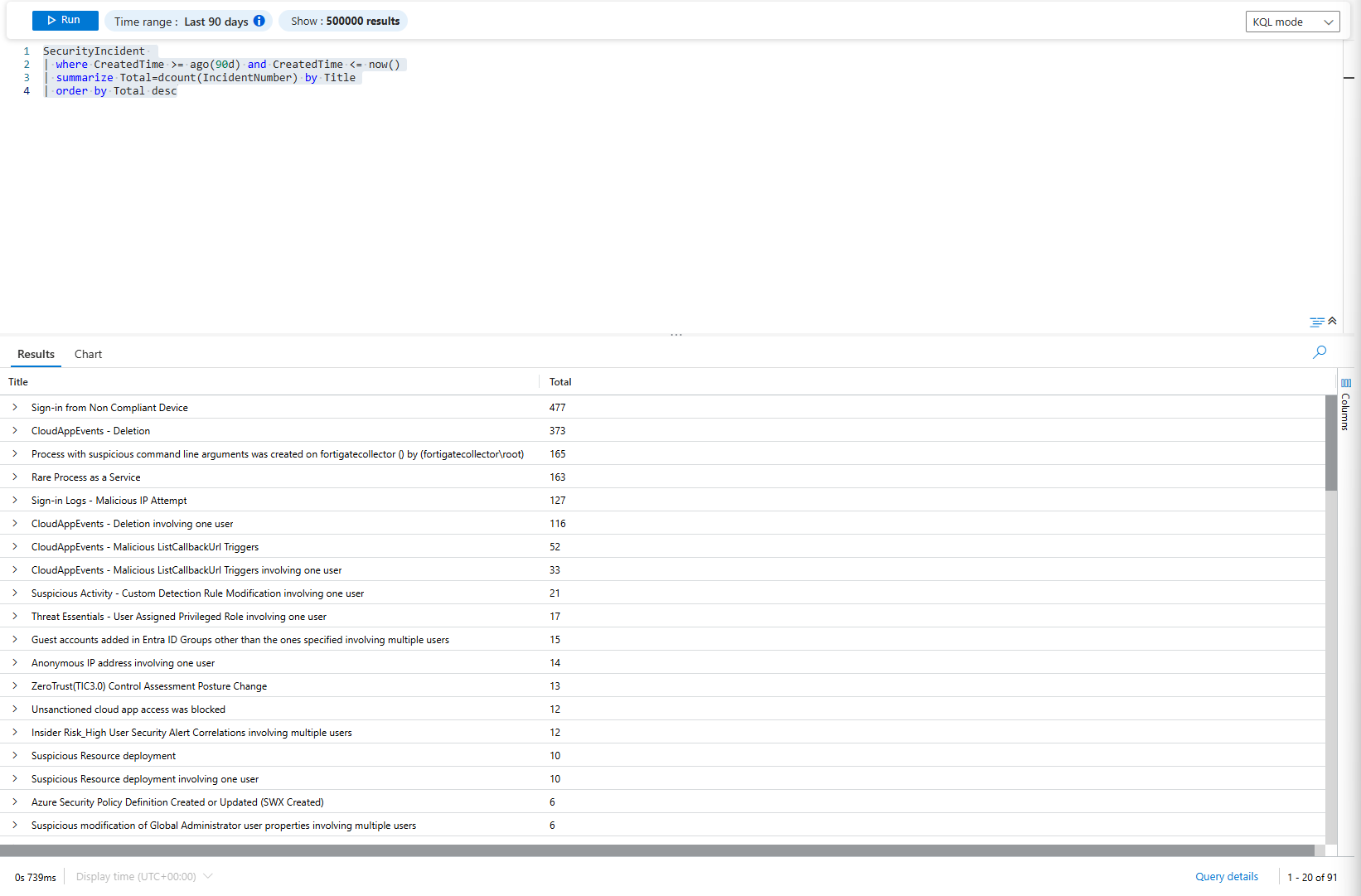
Most of these will be your out-of-the-box detection rules. They're written for every company, which means they're written for nobody. Service accounts are setting them off constantly. Your backup jobs are triggering alerts. Your scheduled tasks are generating false positives.
You need to fix this. And I mean actually fix it, not just raise the threshold and call it a day.
The Process
Talk to your SOC team first. This is important. They're the ones looking at these alerts. They know which ones are useless. Ask them:
- "Which alerts do you just close without investigating?"
- "What keeps firing on the same systems or users?"
- "What would actually help you do your job better?"
They'll tell you. SOC analysts are gold if you actually listen to them. They're in the trenches. They know what's real and what's noise, but they may not have the engineering experience to know that you could actually fix the issue; that's why it's so important to have that open conversation.
Create automation rules to suppress known-good activity. You can do this without touching your base detection rules. "If the alert is 'failed login attempts' AND it's one of these service accounts, close it automatically." You're reducing noise without losing detections.
Then tune the actual rules. Increase thresholds. Add filters. "Failed logins from corporate IP range: ignore. Failed logins from random proxy: alert." You're making the rules smarter, not just softer.
Test it somewhere first. Create a staging workspace and run the changes there for a week before touching production, or automate them with notifications so you can take a look at them when they are triggered, but SOC doesn't have to.
Measure it. After tuning, are you getting fewer alerts? Are the alerts you're getting more useful? Or did you just hide the real attacks?
This takes time. You'll never get it perfect. But you should be constantly improving it. That's maintenance. It may take weeks down the end to tune even one analytic rule, but if that cuts down the number of alerts from 300 weekly to 15, that's well worth it.
Subscribe to the Microsoft Security Blog and Actually Read It
Microsoft puts out updates constantly. New threat intelligence. New analytics rule templates. Updates to detection logic. New connectors. Threat researchers are finding new attack patterns.
And most organisations have no idea these exist because nobody reads the blog.
Go to the Microsoft Security Blog. Subscribe to it. Get it in your RSS reader. Assign someone on your team to read it weekly and tell the SOC what's relevant. If you are a manager or anyone in charge, stop being so picky about the time someone is spending on reading instead of doing the "actual work"; getting insights and more knowledge is crucial in this industry.
Why? Microsoft is releasing things that will directly improve your security posture. New detection templates based on real attacks they've seen. Integration with third-party products like Darktrace or Oracle. New connectors for cloud services. Performance updates. Every month, they publish "Monthly news" covering updates to all their Defender products.
If you're not reading this, you're operating blind.
Your Data Connectors Are Incomplete
You've connected your basic stuff: Azure Activity, Entra ID, Microsoft 365 Defender, maybe some Windows logs.
Now ask yourself: are you missing anything?
Do you have AWS CloudTrail connected? If you're running workloads in AWS (and most companies are), those logs are gold. IAM changes. EC2 provisioning. S3 access. API calls. This is a critical context you're missing if it's not flowing into Sentinel.
Do you have Darktrace connected? If you're using it for network anomaly detection and you're not sending those alerts to Sentinel, you're leaving money on the table. Darktrace catches network threats that traditional rules miss.
Do you have firewall logs? Your perimeter appliances see everything coming in and out. If you're not ingesting those, you have zero visibility into data exfiltration or command-and-control traffic.
DNS logs? VPN logs? Proxy logs? Key Vaults? SQL Databases? Dataverse?
These aren't nice-to-haves. These are visibility. And if you're not ingesting them, you've got blind spots the size of continents.
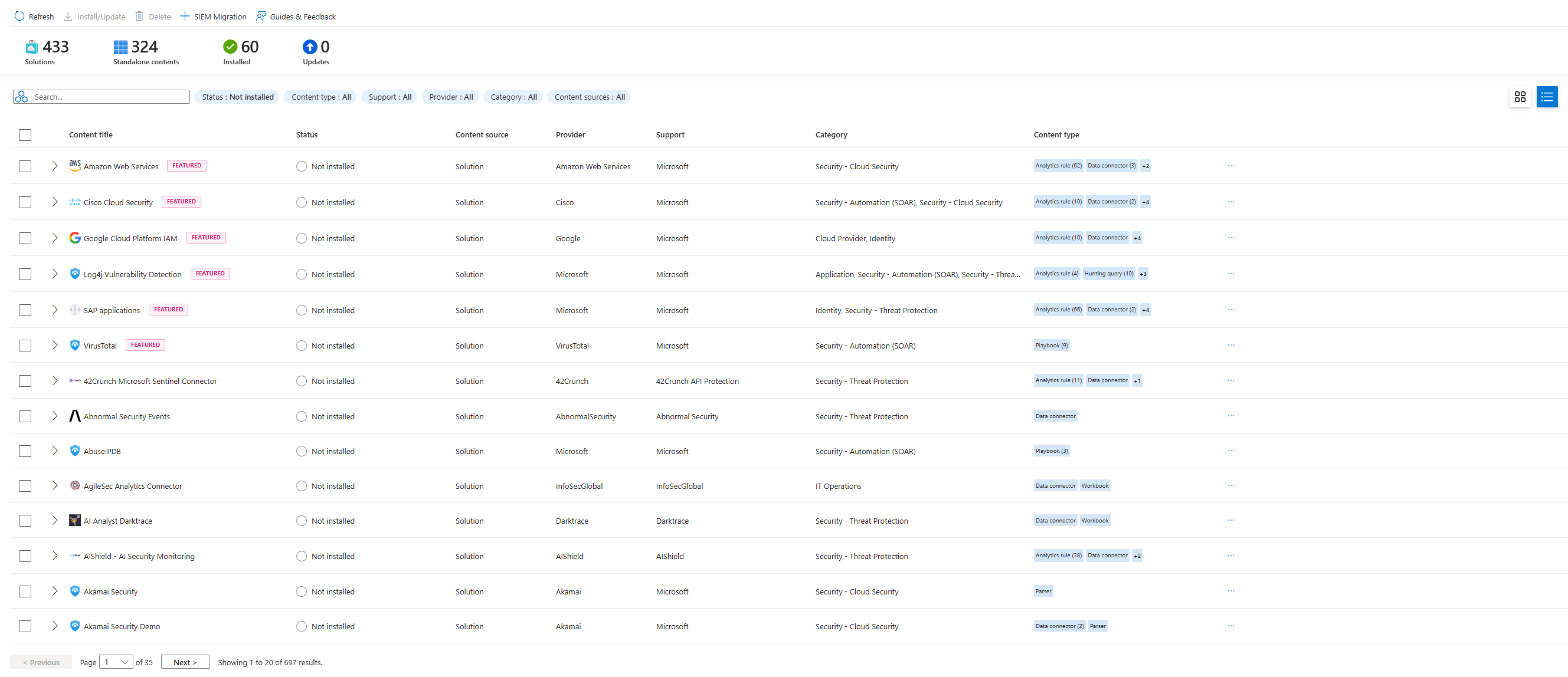
As of October 2025, Sentinel has over 350 native connectors. The data lake is GA, so you can keep more data longer. They added new connectors for GCP, AWS, Alibaba Cloud, Salesforce, Snowflake, and Cisco. If you don't have these, why not?
Before you add a connector, figure out what you'll actually do with the data. "I'm ingesting Darktrace but not creating any rules to use it" = you're just paying for storage. If you're going to connect it, create analytics rules or hunting queries that actually use it.
Let AI Tell You What's Broken
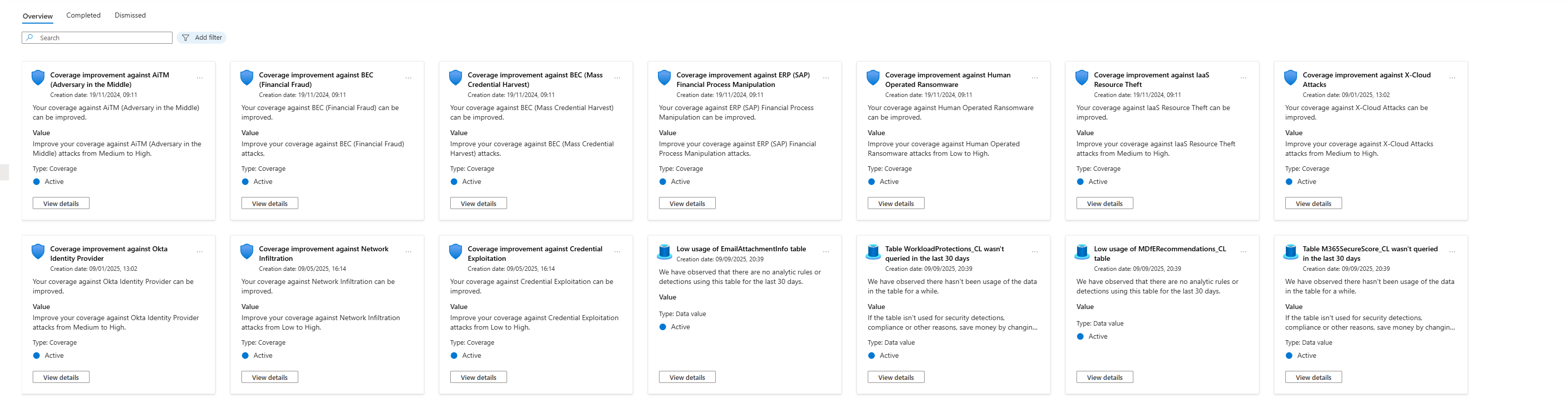
There's a feature in Sentinel called SOC Optimization that most organisations completely ignore.
Go to Microsoft Sentinel > SOC optimization. This analyses your workspace and tells you where you've got coverage gaps. It'll say things like:
- "You're not detecting any ransomware attacks. Here are the rules you should add."
- "You're ingesting this data but have no rules using it."
- "Your coverage against supply chain attacks is zero."
This is your AI telling you exactly where your detection strategy has holes. It's not the best tool out there, but it's one that's already included in the service, so why not at least try using it? You can find a ready guide on how to use it below.

Use it. Create the rules it recommends. Fix the gaps it points out.
Talk to Your SOC Team Like They're Experts (Because They Are)
Set up a monthly meeting with your SOC team. Actual meeting. Agenda:
- What rules are firing too much?
- What coverage do you wish we had?
- What data would help your investigations?
- What's frustrating about the current setup?
Your SOC team knows your environment better than anyone. They see patterns you won't see. They know which alerts are useful and which are theatre.
Ask them if they want visibility into AWS. They'll probably say yes. Ask them if Darktrace would help. They'll know. Ask them about the rules that fire constantly on backup jobs. They've definitely noticed.
Actually listen to them. Act on what they say.
You're Moving to Defender Portal (Eventually)
Microsoft is moving Sentinel to the Defender portal. In July 2026, all Sentinel instances in the Azure portal will redirect to Defender.
This isn't just a UI change. It's unified with Defender XDR. Same alerts. Same incidents. Same playbooks. No more jumping between portals.
If you're still in the Azure portal, start planning now. If you've already moved, make sure your rules and playbooks work properly in the Defender portal.
Custom detection rules in Defender are more powerful than Sentinel automation rules. If you're still building everything as Sentinel automation rules, you're leaving performance on the table.
Create a Maintenance Checklist (And Actually Use It)
Make this a routine. Don't leave it to chance.
Weekly:
- Review your top 10 alert-generating rules. Are they mostly false positives? Tune them.
- Check the Microsoft Security Blog for new stuff relevant to your environment.
- Review incidents you closed. Were they classified correctly?
Monthly:
- Meet with your SOC team. Discuss what's working and what isn't.
- Look at SOC optimization recommendations. Are there coverage gaps?
- Check your data connectors. Are they ingesting properly? Any errors?
- Review costs. Are you ingesting data you're not using?
Quarterly:
- Audit all your analytics rules. Are they still relevant? Do the thresholds still make sense?
- Review automation rules and playbooks. Are they triggering correctly?
- Plan new data source integrations.
Annually:
- Plan your Sentinel architecture for the next year. New workspaces? Consolidation? Federation?
- Review licensing. Are you paying for the right tier?
- Plan your move to the Defender portal if you haven't done it yet.
This seems like a lot. But it's the difference between a Sentinel instance that actually works and one that just looks good in a PowerPoint.
The Hard Truth
Sentinel is not a set-and-forget tool. It requires constant attention. You can't deploy it and forget about it for six months. That's how breaches happen.
The organisations that actually get security right aren't the ones with the fanciest tools. They're the ones who maintain their tools obsessively. Talk to their SOC teams. Those who subscribe to security blogs. That integrates new signals as they become available.
You've built the foundation. Now you have to actually maintain it.
Stop deploying. Start maintaining.
Class dismissed.
