Detection Engineering and Why It's a Must Have

Why Your SIEM Won't Save You Without It
All right class
I've seen people think that you can just turn on Microsoft Sentinel, wiring a few connectors, and enabling the "recommended" analytics rules means they're protected.
They're not.
You end up with terabytes (hopefully much less than that with correct log collection rules) of logs flowing into Log Analytics, a ton of pre-built rules mapped to MITRE ATT&CK, and still, when a real incident hits, nobody sees it until attackers have been roaming around for weeks.
That gap between "we have a SIEM" and "we actually catch attacks" is exactly where detection engineering lives.
MITRE ATT&CK Is a Starting Point, Not Salvation
Everybody loves waving around the MITRE ATT&CK matrix. It's genuinely useful: a shared language for attacker behaviour, a way to map coverage, and a nice way to show your boss colourful diagrams.

But here's the thing nobody likes to admit. You can have "90% ATT&CK coverage" on paper and still miss every meaningful attack. As you can see below, I have a lot of white space for techniques that should be looked at in my environment (keep in mind that in Microsoft Sentinel, MITRE works against Analytic Rules, Hunting Queries and Anomaly Rules - it won't show you any XDR detections that will cover quite a bit of those white spaces)
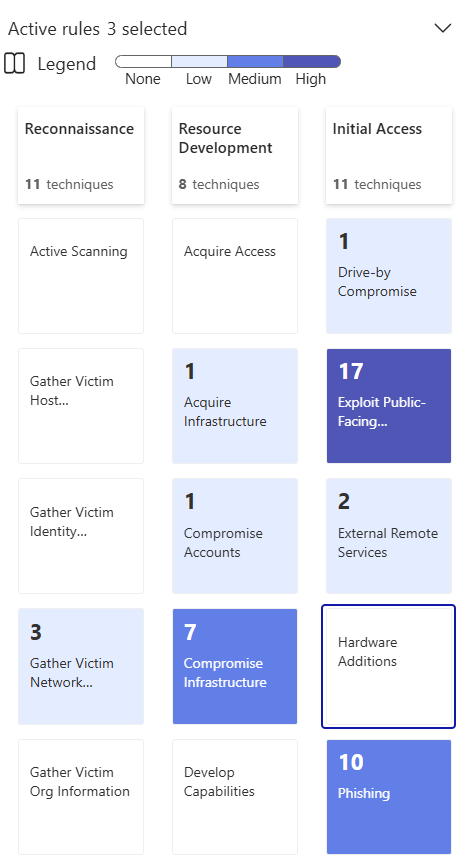
I've seen Sentinel deployments where teams imported every template from the content hub (up to the max limit), and congratulated themselves. Then, a simple credential theft and lateral movement chain walked straight through. The right logs weren't being collected. The rules were never tuned. Half the detections were disabled because they were too noisy.
MITRE ATT&CK is a threat model, not a product. It tells you what behaviours matter. Detection engineering is the job of turning that into reliable, low-bullshit alerts in your actual Sentinel workspace.
Why You Need Detection Engineers, Not Just "Power Users"
Even perfect rules won't help if nobody has time to build, test, and maintain them.
Most orgs try to bolt detection engineering onto the SOC's day job. Level 1s are drowning in alerts. Level 2s are neck-deep in incidents and tickets. Someone says, "Hey, can you also research new attacks and build detections in your spare time?" Yeah, that doesn't happen.
Modern attackers don't sit still. Living-off-the-land abuse of PowerShell, WMI, and LOLBins. Cloud lateral movement using service principals and misconfigured roles. Fileless payloads that never hit disk. Catching that reliably requires constant research, prototyping, and tuning. That's a dedicated role, not an afterthought task.
When detection engineering is actually resourced properly, you catch things at initial access instead of three weeks later when the damage is done. Dwell time drops. Analysts stop closing 300 "expected behaviour" false positives a day and start investigating things that actually matter.
The difference between catching a Kerberoasting attempt on day one versus rebuilding a compromised domain is the difference between a bad afternoon and a catastrophic quarter. That conversation sells the budget ask better than any MITRE coverage diagram.
Detection engineering also means you're hunting for techniques you know attackers are using against your sector, not just praying that Defender's ML model catches it first. That shift from reactive to proactive is the whole point. And if nobody owns it as a named function, it doesn't happen. "Security owns it" means nobody owns it.
What Detection Engineers Actually Do All Day
Strip away the buzzwords. The work is unglamorous and it's a grind.
Research and lab work. Following real incident write-ups, tracking what actual researchers are publishing, and reversing what attackers did step by step. Then running those same techniques in a controlled lab - Mimikatz, Cobalt Strike beacons, malicious macros - and watching exactly how your logging behaves. If you've never done this, you're writing rules based on vibes, not evidence.
Logging validation. Checking whether Sysmon, Defender for Endpoint, Entra ID, and your network stack are actually sending the events your rules depend on. This sounds boring. It is boring. It's also the difference between a detection that works and one that quietly does nothing for six months.
Building and testing rules. Writing KQL, replaying attack traces in the lab, simulating behaviour, and tuning until the signal is good enough to wake an analyst at 2 am without making them want to quit. This takes longer than anyone budgets for.
Continuously pruning and improving. Killing detections that have drifted into uselessness, updating ones that no longer match attacker behaviour, adding new ones as the environment changes. Rules rot. The environment changes. Attackers adapt. Detection engineering is maintenance work as much as it is creative work.
Handling multi-step attacks. Single-event detections are the easy part. Building correlation rules that catch a chain from recon to initial access to lateral movement to exfil requires understanding how the whole kill chain fits together, not just individual techniques.
Treating detections like code. Using Git, Azure DevOps, or Sentinel Repositories to version control rules, push them through dev, test, and prod, and avoid the "edited in production at 3 am" chaos that makes every detection a mystery. If your rules don't have a version history, you don't know what changed or why.
It's the grind that makes all the money you're burning on Sentinel actually worth it.
The Detection Engineering Lifecycle
This is the backbone of the whole series, so it's worth naming the stages before we get tactical.
Requirements discovery is where detection ideas come from, and it's not just "someone read a threat report." Triage is deciding what's actually worth building versus what sounds interesting but won't move the needle. Investigation is the brutal reality check: do you even have the logs this rule needs? Development is writing and iterating the KQL. Testing is proving it works before it wakes the SOC. Deployment is rolling it out, monitoring quality, and looping back.
Every one of those stages is somewhere things go wrong if you're not deliberate about it. Part 2 of this series maps all of this to a concrete Sentinel workflow. For now, the point is that skipping any stage, especially the investigation step, is how you end up with a rule that looks great in the portal and catches nothing in the wild.
Practical Next Steps
If you're reading this at work and want to actually move the needle, start here.
List your current detection owners. Is detection engineering a named responsibility for anyone, or just "whoever has time"? If it's the latter, you already know the problem.
Pull a report of disabled Sentinel analytics rules. Why were they disabled? Noise? Broken logic? Irrelevant data source? That list tells you exactly where your blind spots are.
For the last three real incidents, sit down and write out whether a good detection could have caught this earlier and what data source that rule would have needed. If the answer keeps coming back to "we didn't have the logs to fully investigate," that's a logging programme problem, not a detection problem. Know the difference.
Decide who owns detection engineering as a named function, not as an afterthought bolted onto someone's already full plate.
Class dismissed.
