Microsoft Sentinel: An Incident Just Fired. Now What? (A Beginner's Guide to Investigation)

Welcome back to the command centre, class. So far, you've deployed Sentinel, connected your data, and built your first Analytic Rule. You've essentially set up a network of sophisticated security alarms across your digital world.
And just now, one of them went off.

A new line item appears in the Microsoft Sentinel incident queue. Your heart does a little jump. This is it. This is not a drill. This is why you're here. The system has told you, "Hey, I found something weird. You should probably look at this." NOW.
So, what do you do now? Panic? Run in circles? No. You take a calm, deliberate sip of coffee, and you get to work. Today, we're dissecting our very first incident.
Step 1: Triage and Ownership - "I'll Take This One"
You're in the main Sentinel incident queue. You see a new, unassigned incident. The first thing any good analyst does is take ownership.
Click on the incident, change the Status to "Active", and assign it to yourself as the Owner. This is the universal signal to your team that you're on the case. It prevents two people from wasting time investigating the same thing.
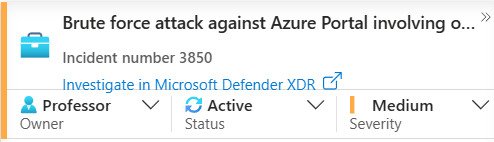
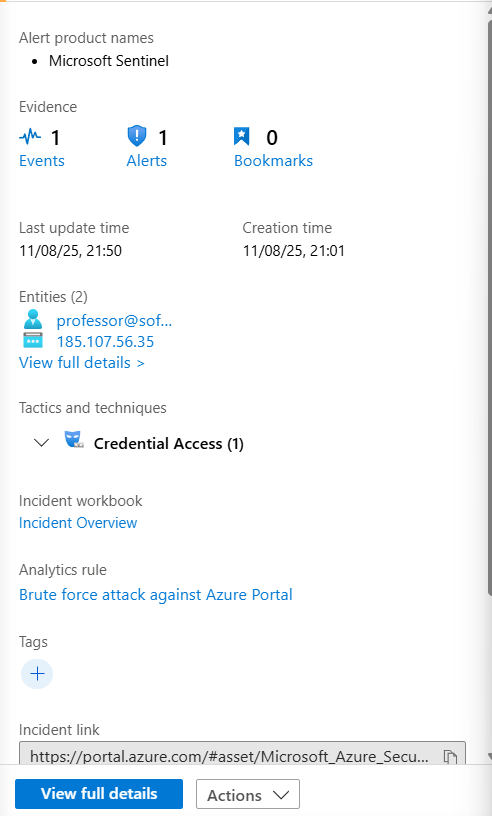
On this initial screen, you get some immediate clues. You see the alert product name—if it says "Microsoft Sentinel," you know one of your own Analytic Rules triggered it. If it says "Microsoft Defender XDR," it means Defender's own brain detected something automatically (well, in most cases, this changes slightly with the new Unified Portal Experience)
You'll also see the Entities involved. Remember how I said mapping entities was crucial? This is why. You can immediately see the user and IP address at the heart of this incident without even clicking further.
Step 2: The Deep Dive - Your New Home in Sentinel
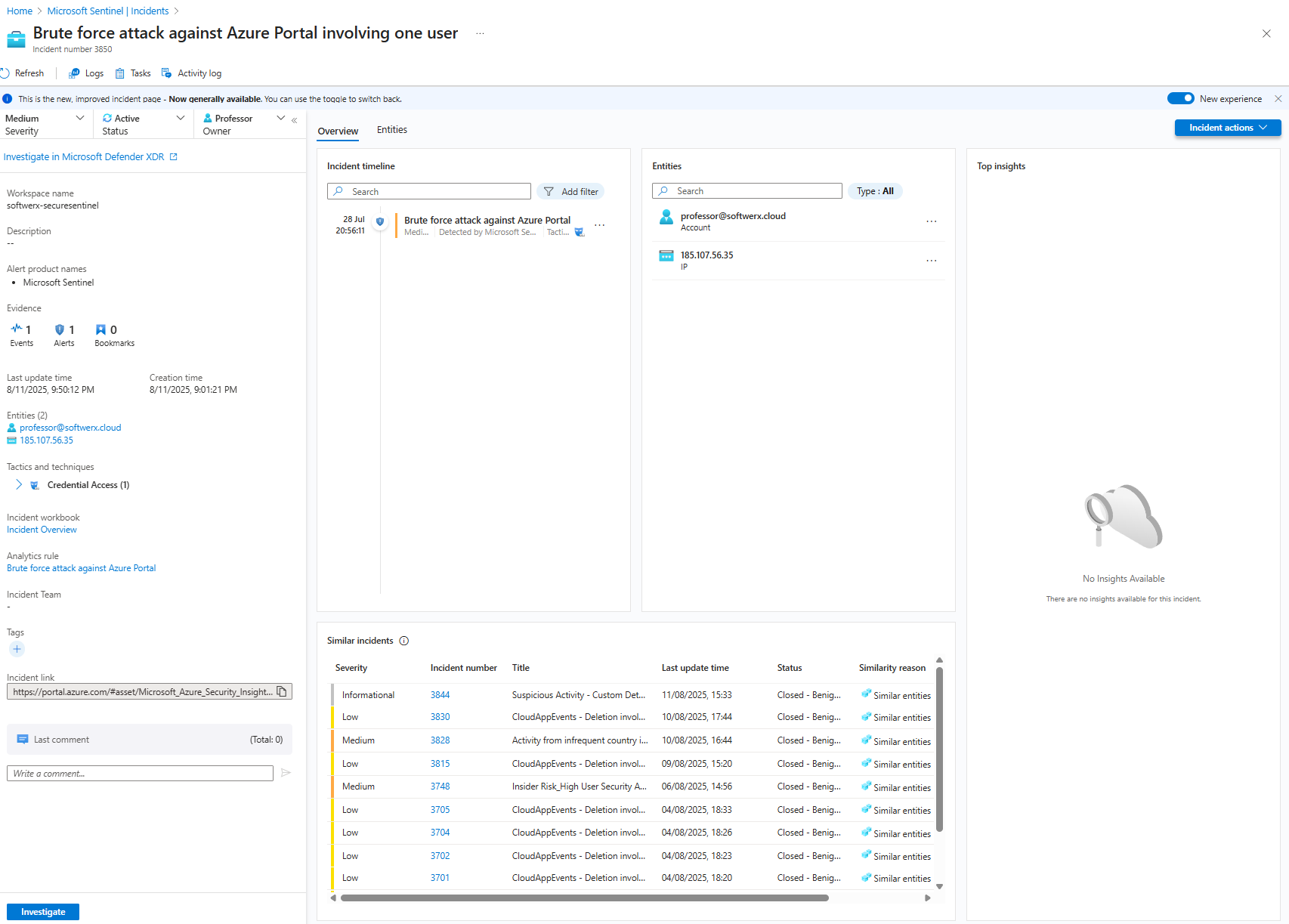
Click on the "View full details" button. Welcome to the incident investigation page. You're going to be spending a lot of time here, so get comfortable. This page is your bread and butter.
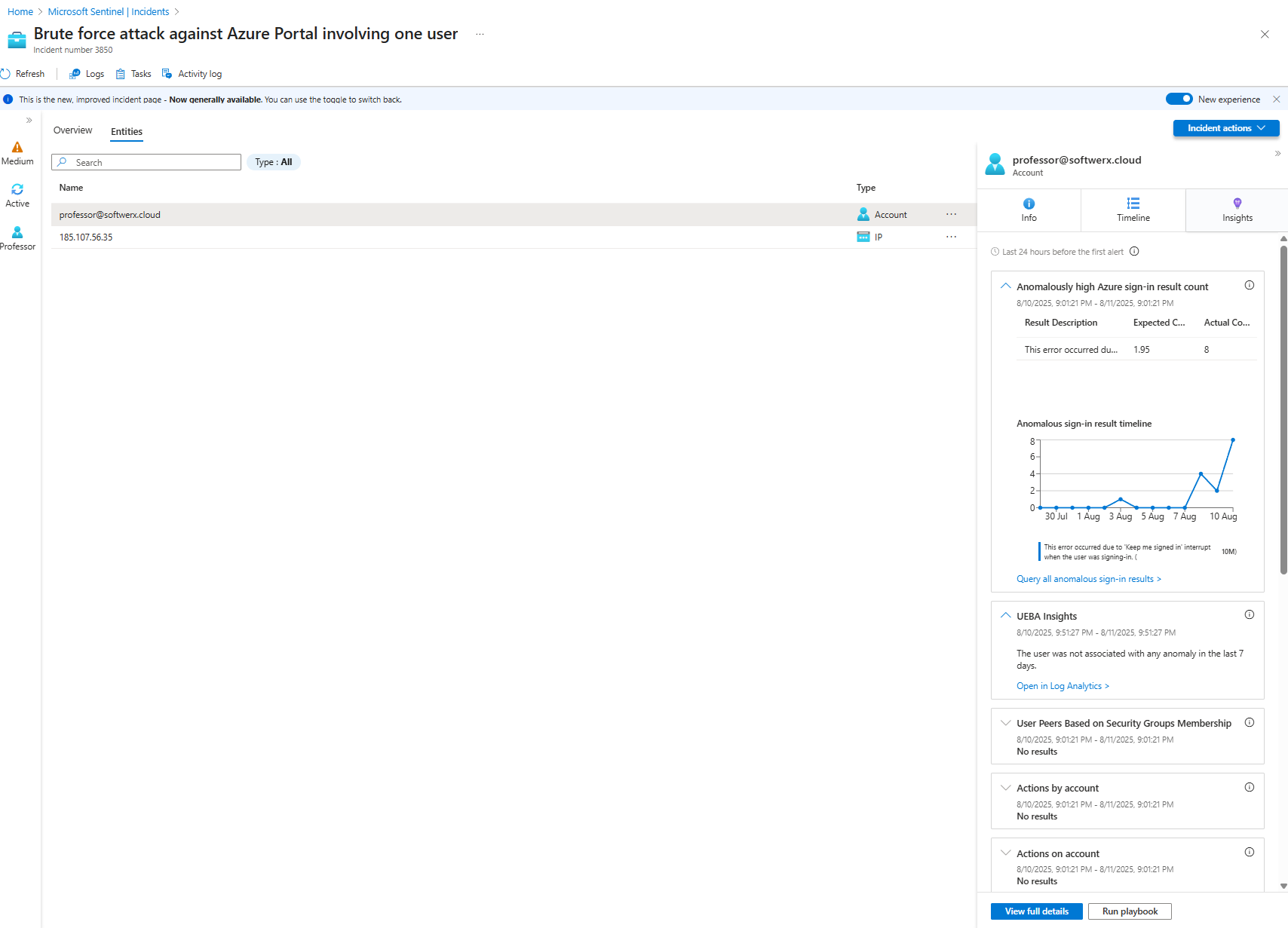
Let's start with the Entities tab again. Click on each one.
- Clicking the User: Sentinel instantly gives you detailed info on this person—their group memberships, recent activities, and other properties.
- Clicking the IP Address: You immediately see where in the world this IP is coming from, along with any threat intelligence matches.
Now, click the "Insights" tab for each entity. This feature is fantastic. It's like having a junior forensic analyst working for you 24/7. For a user, you might see:
- Anomalously high Azure sign-in failures (Hmm, interesting for a brute force attack, isn't it?).
- Unusual resource access or group additions.
- Threat indicators related to the user.
For an IP address, you'll see things like network traffic patterns and connections to other devices. This information alone lets you start asking critical questions: Is this user supposed to be signing in from the Netherlands? Is this a known malicious IP? Who even is this user?
Step 3: Following the Breadcrumbs
Back on the "Overview" tab, take a look at the "Similar incidents" widget. Is this a one-off event, or is it part of a larger pattern? It’s always worth a quick look to see if your incident is related to something bigger.
Don't forget the "Comments" section on the left. If you need to hand this incident off at the end of your shift, this is where you leave your notes for the next analyst. Communication is key.
Now for the real detective work. Let's click on the alert itself and then, in the "Events" section, click "Link to LA" to see the raw logs that triggered this whole thing. The KQL query from the Analytic Rule runs automatically, and you see the evidence. You can see the number of failures, the browser used, the city, the IP... and a field showing the average number of failures for this account is usually 0.4. Today, it's 12.
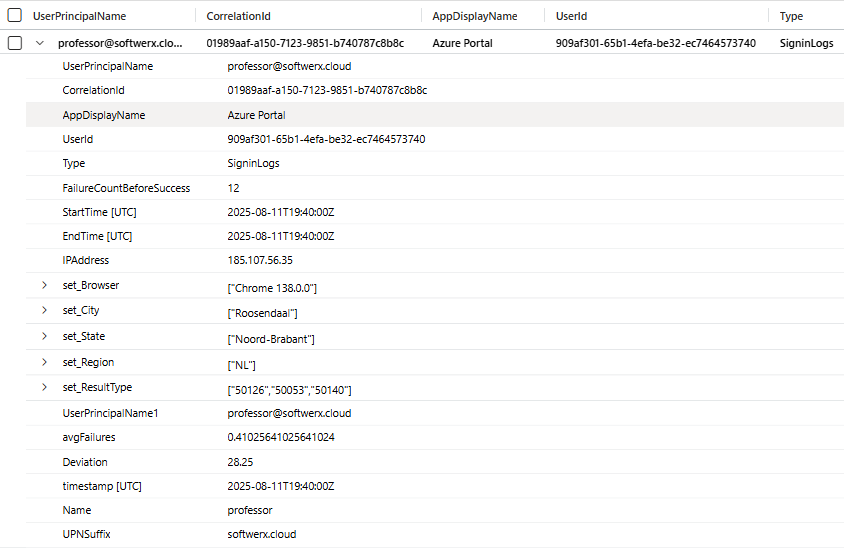
Something is definitely fishy here.

Step 4: KQL to the Rescue - Cutting Through the Noise
The raw logs are great, but sometimes they're too much. Let's refine our search. We can hunt directly in the SigninLogs table to get a clearer picture of what happened around the time of the alert.
Let's start simple:
SigninLogs
| where TimeGenerated >= ago(1h)
| where UserPrincipalName == "professor@softwerx.cloud"This is a good start, but it's a wall of text with dozens of columns. We're getting a lot of clutter. Let's focus on what matters for this investigation.
Let's redefine our KQL:
SigninLogs
| where TimeGenerated >= ago(1h)
| where UserPrincipalName == "professor@softwerx.cloud"
| project TimeGenerated, ResultSignature, ResultDescription, AppDisplayName, IPAddress, MfaDetail, LocationNow we're talking! The project operator lets us pick only the columns we care about. And the story becomes clear. We see multiple failures to the Azure Portal from a single IP address in the Netherlands, all with the reason "Invalid username or password." But wait, we know this user is based in Great Britain.
Then you see it. The last entry. A successful sign-in from that same IP.
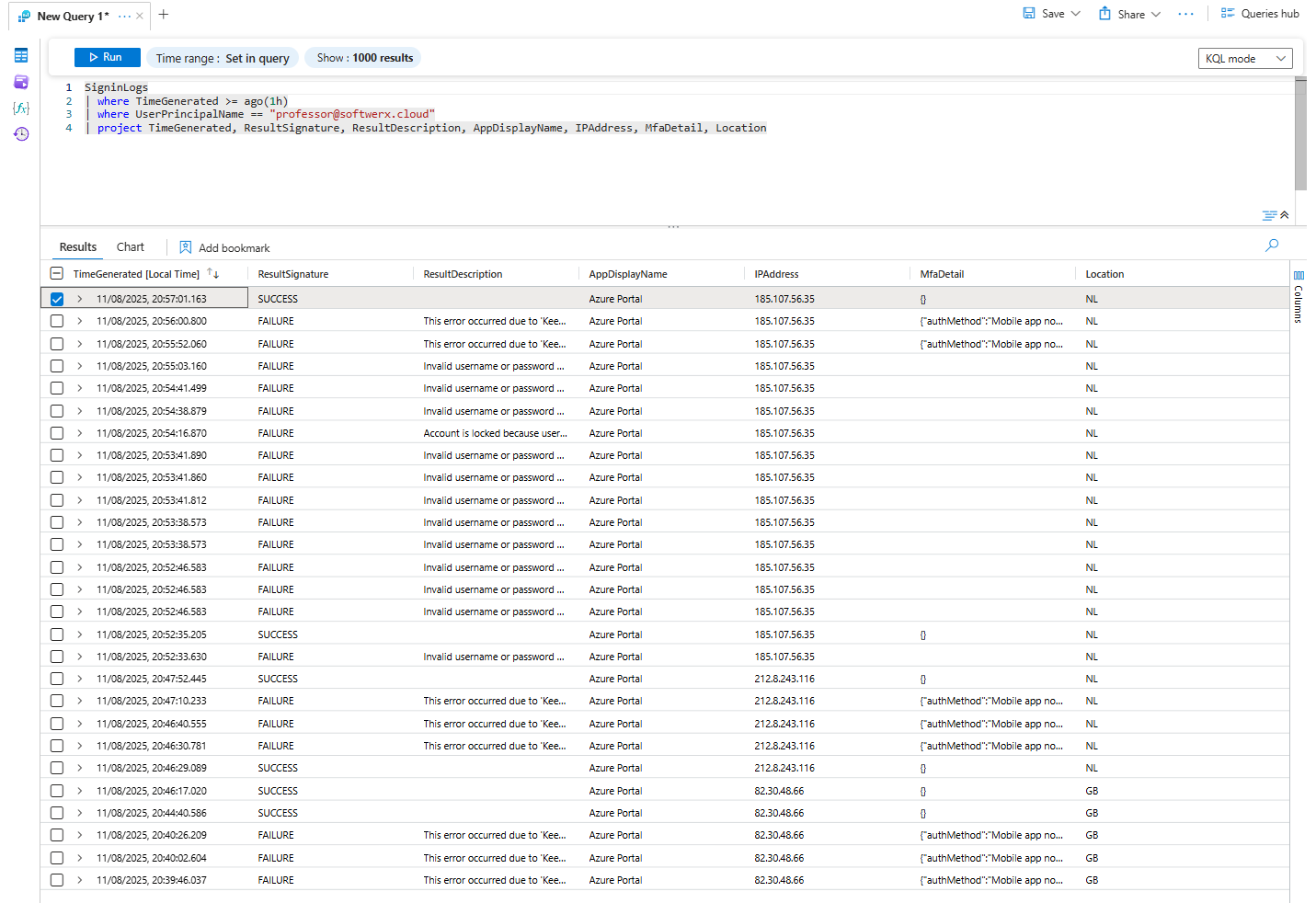
That's bad. Very bad. What's the next step?
Step 5: Act First, Ask Questions Later
This is where the golden rule of incident response comes in: Containment first. You do not have time to message the user and ask, "Hey, are you on vacation?" The attacker who just successfully logged in isn't waiting around for you to be polite.
Your immediate actions should be:
- Block the user account in Microsoft Entra ID.
- Revoke all sign-in sessions and MFA tokens immediately.
This brute force attack looks like a classic MFA fatigue or "push bombing" attack. The attacker had the password and just spammed the user with MFA pushes until they gave in. And yes, before you ask—these users DO EXIST.
Now, with the emergency brake pulled and the attacker locked out, the real work begins. We contained the threat, but we must assume they did something in the time they had access. Our job now is to hunt for their tracks and understand the full scope of the compromise.
This is where you earn your coffee. Let's go hunting with KQL.

The Post-Compromise Hunt: What Did They Do?
We need to answer a few critical questions. We'll use the compromised user's UPN and the malicious IP address as our primary clues.
Question 1: Did they mess with the user's email?
An attacker's first move is often to set up shop in the user's mailbox to maintain persistence or launch further phishing attacks. We need to check for suspicious mailbox rules.
// Hunt for new inbox rules created by the compromised user
CloudAppEvents
| where TimeGenerated > ago(1d) // Look back 24 hours (extend if needed)
| where ActionType == "New-InboxRule"
| where isnotempty(RawEventData['Parameters'])
| extend RuleName = RawEventData.Parameters[0].Value
| extend RuleParameters = RawEventData.Parameters
| where RawEventData.UserId == "compromised.user@domain.com" // <-- The UPN of the compromised account
| project TimeGenerated, AccountDisplayName, RuleName, RuleParametersWhat to look for: Rules that auto-forward all emails to an external address (like a random Gmail account) or rules that auto-delete emails with words like "Warning," "Suspicious," or "Password." This is a classic attacker technique.
Question 2: Did they try to access other resources?
The attacker now has a valid identity. What did they try to open? SharePoint? Azure DevOps? Other applications?
// See what applications the user (or attacker) successfully signed into
SigninLogs
| where TimeGenerated > ago(1d) (you know the drill - change if needed)
| where UserPrincipalName == "compromised.user@domain.com"
| where ResultType == 0 // '0' means success
| summarize make_set(AppDisplayName) by IPAddress
| extend AppsAccessed = strcat(set_AppDisplayName, ", ")
| project IPAddress, AppsAccessedWhat to look for: The malicious IP address accessing applications that the user normally doesn't touch. If Dave from Marketing, who only uses SharePoint, suddenly accesses the Azure Portal or a developer tool, that's a massive red flag.
Question 3: Did they try to elevate their privileges?
This is the big one. Attackers want power. They'll try to add themselves to high-privilege groups to gain more access.
// Check if the user was added to any new groups
AuditLogs
| where TimeGenerated > ago(1d)
| where OperationName has "Add member to group"
| extend TargetUser = tostring(TargetResources[0].userPrincipalName)
| extend GroupName = tostring(TargetResources[0].displayName)
| extend Actor = tostring(InitiatedBy.user.userPrincipalName)
| extend Service = tostring(InitiatedBy.user.displayName)
| where TargetUser == "compromised.user@domain.com"
| project TimeGenerated, OperationName, GroupName, TargetUser, Actor, Service, IdentityWhat to look for: The compromised user being added to any group with "Admin," "Global," "Privileged," or "Security" in the name. You should also check if the user themselves tried to add other accounts to groups.
Question 4: Did they access any sensitive files?
If they got into SharePoint, what did they look at?
// Hunt for file access events from the malicious IP/username
CloudAppEvents
| where TimeGenerated > ago(1d)
| where ActionType in ("FileAccessed", "FileDownloaded")
| where Application == "Microsoft SharePoint Online"
| extend IPAddress = RawEventData.ClientIP
| extend UserName = tostring(RawEventData.UserId)
| where IPAddress == "0.0.0.0" // <-- The malicious IP address
// where UserName == "compromised.user@domain.com" // <-- or use the username logic instead of IP
| summarize make_set(FileName) by UserNameWhat to look for: Access to files with sensitive names like "Passwords.xlsx," "Q4 Financials," or "Payroll"
The Final Step: Resolution and Reporting
Only after you have completed this hunt and are confident you understand the full scope of the attacker's actions can you move to final resolution.
Now, you can get in touch with the user, have that "great" conversation while re-enabling their account, and force a password reset.
All that's left is to close off the incident in Sentinel. But now, your closing notes are not just "User clicked a link." They are a detailed, professional summary:
"True Positive. Brute force followed by a successful MFA fatigue attack from IP 175.45.176.82. Account was contained. Post-compromise investigation revealed no evidence of mailbox rule creation, privilege escalation, or sensitive file access. User password has been reset, and the manager has been notified about potential password leakage, which will be checked by the TI team. The user will be enrolled in additional Cybersecurity training. Closing incident."
Congratulations. You haven't just closed a ticket. You've performed a full-cycle incident response. You've stared into the abyss, understood the story, hunted the ghost in the machine, and protected your environment.

Now... onto the next incident